

(English blog: August 2025 Update on Generative AI Translation Quality | One World Link)
多くの企業でDX推進の一環として、コスト削減や業務効率化を目的に生成AIを導入されているかと思います。DeepL、ChatGPT、Geminiなどを使って、日本語から英語への翻訳に生成AIを活用されている企業も多いことと思います。
では、2025年夏時点における生成AIによる日英翻訳の現状はどうなっているのでしょうか?
我々OWLの翻訳チームは、生成AIや機械翻訳の活用にかなり精通しております。最近、翻訳品質において、見逃せない特徴や傾向がいくつか見られるようになってきました。本ブログでは、実際に私たちが遭遇した生成AI・機械翻訳による翻訳の不自然な例や問題点をいくつかご紹介していきたいと思います。すべての例は、実際のスクリーンショットに基づいており、特にIRやコーポレートコミュニケーションで生成AIを使用する際に注意すべきポイントを明らかにします。
ポイント1:シンプルな部分こそ見逃さない
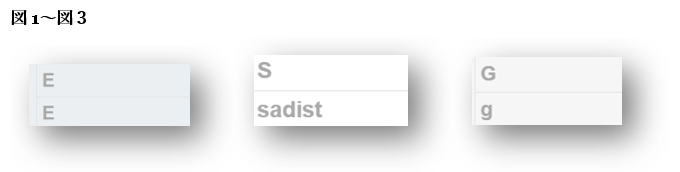
図1〜図3は、「ESG」という略語がレイアウトの都合で3行に分かれていたため、機械翻訳ツールがそれぞれを「E」「sadist」「g」と訳した例です。「S」が「sadist(サディスト)」を意味するとは、当然どの翻訳者も思わないでしょうが、それでもこの結果は見過ごせません。 大文字・小文字の不統一や、単なるアルファベットが突然単語として訳されてしまう現象は、ちょっとしたフォーマットの違いで生成AIの出力が大きく崩れることを示しています。短い語句やシンプルな内容ほど安心しがちですが、AIが正しく処理できるとは限りません。こうした箇所こそ、一貫性を持って丁寧にチェックすることが重要です。

図4〜図6は、機械翻訳でよく見られる別の問題、「辞書的な出力」の例です。
これらの翻訳は、技術的に「誤訳」ではないものの、過剰な説明、かっこ書き、冗長な定義が含まれており、ビジネス文書としては不適切な表現になっています。さらに、今回のケースでは、そもそも翻訳された意味が文脈と合っていませんでした。正しい訳語は以下の通りです。
- 支える → Support
- なし → N/a
- ときめっく → TTOKIMEKKU
補足:元の日本語では「ときめっく」は施設名として使用されていた固有名詞でした。
生成AIは、固有名詞、定訳、業界特有の用語を正しく処理するのが苦手な傾向があります。特に公式文書においては、こうした用語がどのように扱われているかを必ず確認することが重要です。
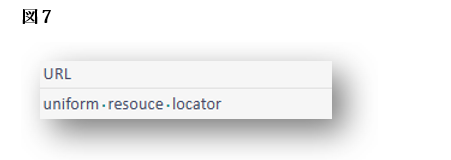
図7では、「URL」が「uniform resource locator」と訳されていますが、これは英語ではほとんど使われない表記です。
「URL」という表現が一般的であり、わざわざ正式名称を綴る必要はありません。
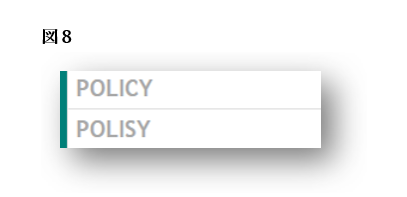
図8については、残念ながら説明の必要すらありません。「Polisy」は、「policy」の完全な綴りミスであります。
ポイント2:数値は必ず二重・三重に確認する
生成AIが数値を完全に誤ることもあります。さらなる事例については、こちらのブログをご覧ください。(日本語:こちら 英語:こちら)
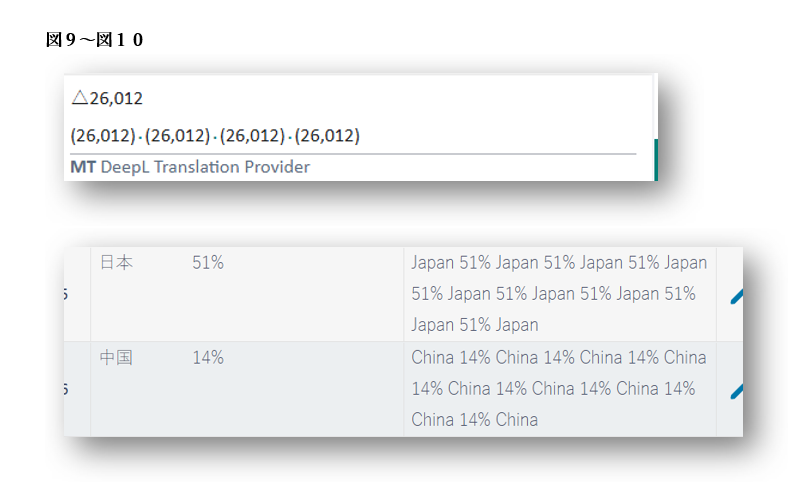
図9および図10では、数値そのものは正しいにもかかわらず、翻訳ツールが同じ数値を4〜8回繰り返して出力している例が確認できます。数値が正確でも、このような繰り返しは誤りであり、文書全体の信頼性に影響を与える可能性があります。数値の出力は、必ず細かく確認するようにしましょう。

図11および図12では、さらに重大な誤訳が見られます。「¥」が「$20」と訳されていたり、「万人」が「million people(100万人)」と誤って訳出されています。
これらの誤りは、単体で見ればすぐに気づくレベルですが、長文の財務資料の中に埋もれていると見落とされる可能性があります。特に、英語部分だけを文法や表現の自然さの観点からチェックしている場合は、数値や単位の誤りに気づきにくくなります。
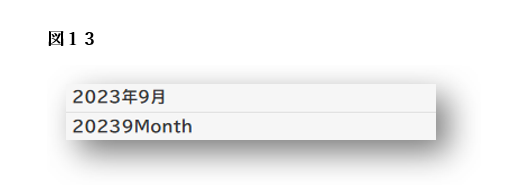
図13は、単純な日付に対する不可解な翻訳の例です。
「20239Month」という表記からは、翻訳ツールが日本語の日付を構成要素ごとに個別に処理し、それをスペースなしで結合してしまったことがうかがえます。
この翻訳は、「month」の使い方も不自然であるうえ、英語として必要なスペースが完全に欠落しており、通常の英文書式とは大きく異なる非標準的な出力となっています。
ポイント3:明らかに不適切な単語の誤訳に注意する

図14および図15では、「お得(otoku)」が「オタク(otaku)」に、そして「共食」が「cannibalism(カニバリズム)」に誤訳されています。
この2つの例については、あえて説明するまでもなく、完全に誤っており、場合によっては非常に不適切な表現となり得ます。こうした誤訳が含まれてしまうと、文書全体の信頼性に関わる問題となる可能性があります。
これらの誤訳は、生成AIが不正確、または確認不足の公開翻訳データを学習してしまった結果である可能性があります。質の低い出力がそのまま再利用され、AIの訓練データに取り込まれていくことで、こうした誤りが以前よりも頻繁に見られるようになってきています。

図16では、多くのIR資料に共通して登場する用語「中期経営計画」が、「Midterm Corporate Strategy」と訳されています。
「中期経営計画」の標準的な英訳は 「medium-term management plan」 です。
まず第一に、「midterm」は複合形容詞として使う場合、ハイフンを入れて“mid-term”と表記すべきです。
そして、より重要なのは、この“Midterm Corporate Strategy”という表現が、特定企業が独自に使用している公式名称である可能性が高いという点です。
つまり、翻訳ツールがこの訳語を過去の公開情報から“学習”した可能性があるということになります。
OWLがこれまでに生成AIや機械翻訳を使用してきた中で、「中期経営計画」がデフォルトで“Midterm Corporate Strategy”と訳されたケースはこれまで一度もありません。
これは、生成AIが一般的な定訳ではなく、企業固有の表現や公開資料上の訳語を取り込んで出力に反映させていることを示す例かもしれません。
このように、非標準の訳語が公開されたまま訂正されない場合、それがAIの学習データに取り込まれ、“正しい訳”として出力されてしまう可能性があります。
これはいわゆる「Garbage in, garbage out(質の低い入力からは質の低い出力しか得られない)」という典型的な問題であり、AIが不適切な入力を学習すればするほど、今後さらに誤訳が増えていくリスクがあることを意味しています。
→「中期」を“mid-term”と訳すのが不適切な理由は、当社ブログでご紹介しています。(こちら)
ポイント4:スペースの抜け漏れに注意する
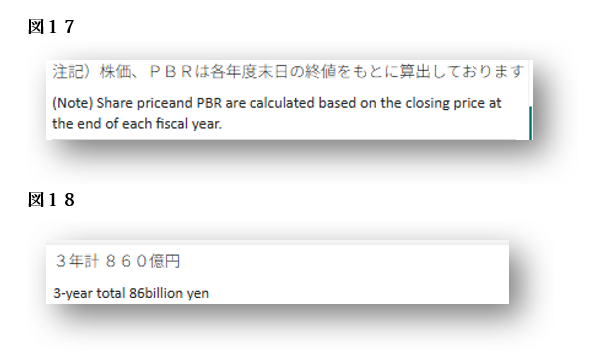
図13では、日付の中でスペースが抜け落ちる例をご紹介しましたが、図17および図18では、文全体におけるスペースの抜けが見られます。
図17の例では、「price」と「and」の間にスペースがなく、図18では、数値(86)と単位(billion)の間のスペースが欠落しています。
一見すると小さなミスに見えるかもしれませんが、読みやすさに影響を与えるだけでなく、正式な文書としての印象を損ねる可能性があります。
また補足として、使用するスタイルガイドや文脈によって異なる場合はありますが、英語では10未満の数字は本文中ではスペルアウト(単語で表記)されるのが一般的です。
さらに、「3-year total」のようなハイフンでつながれた形容詞句は、通常「three-year」のようにスペルアウトして表記するのが適切とされています。
なぜこうした問題が起きるのか?
こうした翻訳品質のばらつきには、2つの要因があると私たちは考えています。
第一に、生成AIが過去に自ら出力した質の低い翻訳結果を、ユーザーが確認せずにそのまま受け入れたことにより、それを「正しい」と学習してしまっている可能性があります。
第二に、生成AIが公開されている翻訳例、いわゆる「野良翻訳」から学習すればするほど、質の低い翻訳(いわゆる“ガベージ”)が、正しい用例として取り込まれてしまうリスクが高まると考えられます。
このような傾向は、データ品質の専門家が警鐘を鳴らしている現象とも一致しています。Melissa社のスペシャルプロジェクト担当シニアディレクター、Robert Stanley氏は、2025年6月2日付のSD Timesの記事の中で次のように述べています。
「AIモデルを質の低いデータで訓練すれば、当然のように悪い結果を得ることになります。」
また、Stanley氏は、「データが正確で、完全で、補足情報がきちんと付加されていなければ、AIの出力結果は信頼できないものになる」とも強調しています。
つまり、「Garbage in, garbage out(質の低い入力からは質の低い出力しか得られない)」という原則は、いまだに強く当てはまるのです。
さらにStanley氏は、LLM(大規模言語モデル)はユーザーを満足させようとする性質があるため、「見た目には正しそうに見えるが、実際には誤りである回答を返すことがある」と警告しています。
[出典:SD Times, “Garbage in, garbage out: The importance of data quality when training AI models”(2025年6月2日)https://sdtimes.com/data/garbage-in-garbage-out-the-importance-of-data-quality-when-training-ai-models]
生成AIや機械翻訳ツールの翻訳品質に関する問題の背景には、学習データの質と出所が関係している可能性もあります。
Nature誌に掲載され、Financial Timesが報じた最近の研究では、過去のAIが生成したコンテンツ(=合成データ)を学習データとして使用した場合、AIモデルが「モデル崩壊(model collapse)」を起こすリスクがあると指摘されています。
こうしたモデルは、訓練を重ねるごとに自分自身の過去の誤りを強化してしまい、ゆがんだ出力や意味不明な出力につながる可能性があります。
翻訳の分野では、これにより不自然、誤訳、あるいは直訳的すぎる表現があたかも標準的な英語のように学習・出力されてしまうことが懸念されます。
[出典:Financial Times “Model collapse: how AI models trained on synthetic data can quickly degrade.”(2024年7月25日) ※Nature誌に掲載された研究に基づく報道 https://www.ft.com/content/ae507468-7f5b-440b-8512-aea81c6bf4a5]
まとめ
翻訳ツールは年々進化していますが、信頼性の面では依然として課題が多く残っています。特に、公開された不正確または一貫性に欠ける翻訳データから“学習”している場合には、そのリスクがさらに高まります。
こうした自己強化的な誤りが蓄積されることで、非標準的、または誤解を招くような訳語が“正しい表現”として定着してしまう恐れがあります。
一見些細な不一致であっても、数値の誤訳や不適切な単語の使用が含まれていれば、それだけで翻訳全体の品質や信頼性が損なわれる可能性があります。
このような時代だからこそ、翻訳結果のリスクを見逃さず、自然で明確かつプロフェッショナルな英語で伝えるための対策がこれまで以上に重要です。
翻訳の品質に不安がある場合や、第三者によるチェックが必要な場合は、OWLのネイティブ翻訳チームがサポートいたします。貴社の英語資料が正確で、投資家に伝わる内容になっているかどうか、ぜひお気軽にご相談ください。
Mia Omatsuzawa 大松澤実絵
最新記事 by Mia Omatsuzawa 大松澤実絵 (全て見る)
- 日本語レポートの英語表記、本当に正しいですか? - 12月 15, 2025
- 英語をより自然に見せるための簡単な方法の一つ - 12月 13, 2025
- なぜ統一したテーマ設定が統合報告書のメッセージ性を高めるのか - 12月 11, 2025
- 縦組みデザインは英語レポートの読みやすさを損なう理由 - 12月 9, 2025
- 何を書くかだけでは伝わらない:「どう書くか」が重要 - 12月 5, 2025