

Is your company incorporating generative AI as part of the DX push to save time and money? Like many companies, you might be using DeepL, ChatGPT, Gemini, or other generative AI to translate Japanese into English. But what’s the state of generative AI Japanese-to-English translation as of summer 2025?
OWL translators are no strangers to generative AI or machine translation. Lately, we’ve noticed some quirks in quality that users should know about.
In this blog post, I’ll share several real examples of odd or problematic translations we’ve encountered. These issues highlight what to watch for when using AI translation tools for Japanese-to-English translation, especially for IR or corporate communications. All examples are taken directly from screenshots we’ve collected.
Tip 1 – Don’t skip the simple stuff

Figures 1–3 show the acronym ESG split across three lines, which led the machine translation tool to render the letters as “E,” “sadist,” and “g.” While no human translator would assume “S” stands for “sadist,” this still raises red flags.
The capital/lowercase inconsistency and the shift from a letter to a word show just how fragile AI output can be, especially with simple formatting quirks. Don’t assume short or seemingly simple content will be handled correctly. Always check for consistency.

Figures 4–6 show another common issue: dictionary-style output. These translations aren’t technically “wrong,” but they include excessive explanations, parentheses, or wordy definitions that don’t belong in the context of a professional document. In fact, the machine translation used the wrong definitions entirely. The correct translations in context were as follows:
支える→ Support
なし → N/a
ときめっく→ TTOKIMEKKU
Note: In the original Japanese, ときめっく was used as a proper noun (the name of a facility). AI often struggles with proper nouns, fixed translations, and company- or industry-specific terms. Always double-check how these are handled, especially in official documents.
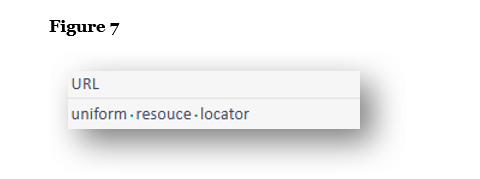
In Figure 7, the translation spells out “URL” as “uniform resource locator,” something rarely done in English. There is no reason to spell this out when URL is the common term.
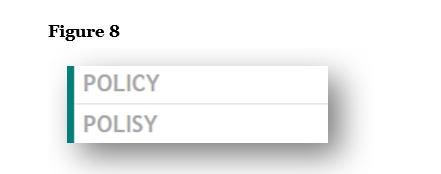
Figure 8, unfortunately, requires no explanation and is entirely unacceptable. “Polisy” is simply a misspelling of “Policy.”
Tip 2 – Double and triple check your numbers
Sometimes generative AI gets numbers completely wrong.
→See our blog here for more examples in English and Japanese
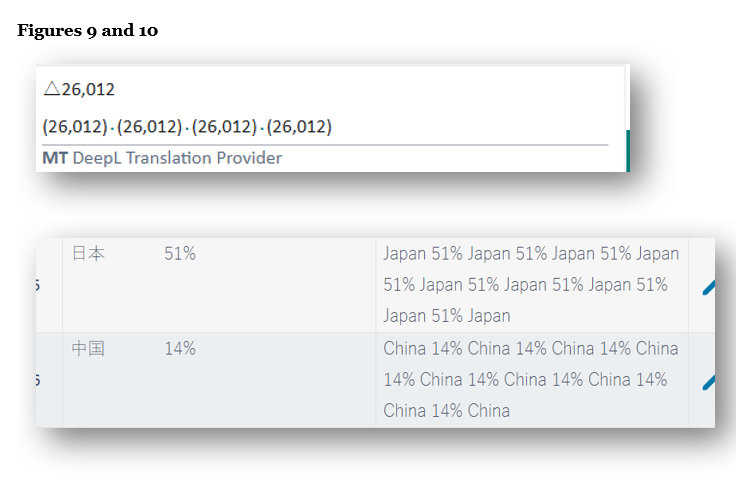
Figures 9 and 10 show examples where the translation tool repeats a number four to eight times. The number itself is correct, but the repetition is not. Always check numerical output carefully.

Figures 11 and 12 show more serious mistranslations: ¥ converted to “$20,” and 万人 translated as “million people.” These are easy to catch in isolation but could easily be missed in a lengthy financial report, especially if only the English output is reviewed for grammar, word choice, and natural language use.
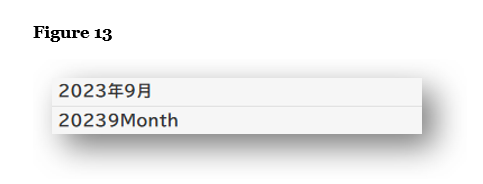
Figure 13 shows a bizarre translation of a simple date. “20239Month” suggests the tool tried to translate each part of the Japanese date individually, then collapsed them into a single unreadable string. This translation is non-standard in the use of “month” as well as the lack of spaces.
Tip 3 – Watch out for the occasional completely wrong and inappropriate word

Figures 14 and 15 here depict “otoku” translated as “otaku” and 共食 translated as cannibalism. I probably don’t have to explain why this is wrong. Mistakes like these are potentially embarrassing.
These two examples may be examples of generative AI learning from incorrect or poorly reviewed public translations. As more flawed outputs get recycled into training data, we’re beginning to see these types of errors surface more frequently.

Figure 16 shows 中期経営計画, a term common to most investor relations documents, as “Midterm Corporate Strategy.” The standard English translation for 中期経営計画 is “medium-term management plan.”
First, midterm should be hyphenated when used as a compound adjective (i.e., “mid-term”).
Second, and more importantly, this phrase appears to reflect the official English name a specific company uses for its own medium-term management plan. In other words, the tool has likely “learned” this translation from prior public use, despite it being nonstandard.
In all our years working with generative AI and machine translation tools, we’ve never seen 中期経営計画 rendered as Midterm Corporate Strategy by default. This may be another example of how generative AI draws from real-world usage, including company-specific terms, even when they don’t align with standard or widely accepted translations. If a nonstandard translation is used publicly and goes unchecked, it can be absorbed into the AI’s training data and later offered as a “valid” translation. This reflects a classic garbage-in, garbage-out problem: the more flawed inputs the model is exposed to, the more likely it is to produce flawed outputs in the future.
→Find out why “mid-term” is the incorrect translation for 中期 on our blog (English + Japanese)
Tip 4 – Check for missed spaces

Figure 13 showed how machine translation can omit spaces within a date. Figures 17 and 18 reveal similar spacing issues in full sentences. The sentence in Figure 17 is missing a space between “price” and “and,” while in Figure 18 we are missing a space between the number (86) and unit (billion).
These may seem like minor errors, but they can affect readability and look careless in formal documents. Allow me to also note that, while it depends on context and the style guide in use, numbers under 10 are generally spelled out in body text. Hyphenated adjectives like “3-year total” are typically written as “three-year.”
So why is this happening?
We suspect two reasons for the quality quirks. First, we think that generative AI may be becoming self-referential, “learning” from its own past low-quality output accepted blindly by users. Second, we suspect that the more generative AI learns from translations “in the wild,” the more “garbage” (low-quality) translations generative AI comes to accept as correct examples.
These phenomena align with warnings from data quality experts. As Robert Stanley, Senior Director at Melissa, explains in a recent SD Times article , “If you’re training your AI model on poor quality data, you’re likely to get bad results.” He also stresses that without data that is “accurate, complete and augmented or well-defined… the outputs of the AI model won’t be reliable.” In other words, garbage in, garbage out still holds true.
Stanley also notes that LLMs are often designed to please the user, which “sometimes means giving answers that look like compelling right answers, but are actually incorrect.”
[Source: SD Times, “Garbage in, garbage out: The importance of data quality when training AI models” Published June 2, 2025. https://sdtimes.com/data/garbage-in-garbage-out-the-importance-of-data-quality-when-training-ai-models]
The source and quality of training data used in generative AI and machine translation tools may be to blame for these quality issues as well. As highlighted in recent research published in Nature and reported by the Financial Times, AI models trained on synthetic data—content generated by earlier versions of AI—are at risk of what researchers call “model collapse.” Over successive training cycles, these models can begin to reinforce their own mistakes, leading to distorted or nonsensical outputs. In translation, this could mean that awkward, incorrect, or overly literal machine-translated phrases become embedded as standard over time.
[Source: Financial Times. “Model collapse: how AI models trained on synthetic data can quickly degrade.” Published July 25, 2024. Based on research originally published in Nature. https://www.ft.com/content/ae507468-7f5b-440b-8512-aea81c6bf4a5]
To Summarize
Translation tools are becoming more advanced, but they are still quite unreliable, especially if they are “learning” from flawed or inconsistent public content. Over time, these self-reinforcing mistakes can lead to nonstandard or even misleading translations becoming normalized.
Whether the issue is a small inconsistency, a mistranslated number, or an entirely inappropriate word, even one error can affect the quality and credibility of your translations. It is more important than ever to stay alert to these risks and take steps to ensure the final English reads naturally, clearly, and professionally. If you’re unsure about the quality of a translation, or need a second set of eyes, our team of native English translators can help you make sure your materials are accurate and investor-ready.
Jessica Azumaya
最新記事 by Jessica Azumaya (全て見る)
- October 2025 Update on Generative AI Translation Quality - 8月 7, 2025
- Mastering Sentence and Paragraph Length - 8月 7, 2025
- Do You Create Reports for Both Types of Readers in the West? - 6月 17, 2025
- June 2025 Quiz Answers - 6月 11, 2025
- Meet 10 ESG Players You Need to Know - 5月 29, 2025